Die „relationale Denke“ von Codd. Codd stellt in seinem Aufsatz von 1970 die relationale Denkweise der in den 70ern üblichen graphenorientierten Denkweise gegenüber. In der graphenorientierten Sichtweise werden Daten als Knoten und Beziehungen zwischen den Daten als Kanten dargestellt. Das führt dann zu den hierarchischen Datenmodellen. Ebenso war es früher üblich, dass die logische Struktur der Daten eng mit der technischen Organisation der Daten auf dem Datenträger verknüpft war. Davon wollte Codd loskommen, insbesondere, weil durch die Verknüpfung eine Fachfrau für Daten auch gleichzeitig eine Fachfrau für Computertechnik sein musste. Die Fachleute sollten sich auf die logische Sicht der Daten konzentrieren können. Im Weiteren lernen Sie nun der Weg von unstrukturierten Daten zu einem relationalen Modell anhand eines lebensweltlichen Beispiels in drei Schritten kennen.
Stand: 22.05.2021
Zum Überblick über die Methoden der Wirtschaftsinformatik
Einordnung des Coddschen Relationenmodells in ARIS
In der Visualisierung des Aris-Rahmenkonzepts, dem „ARIS-Haus“, finden Sie auf der linken Seite die Daten-Perspektive. Das Relationenmodell von Codd ist in der Daten-Perspektive in der Beschreibungsebene „DV-Konzept“ eingeordnet (Abb. 1).
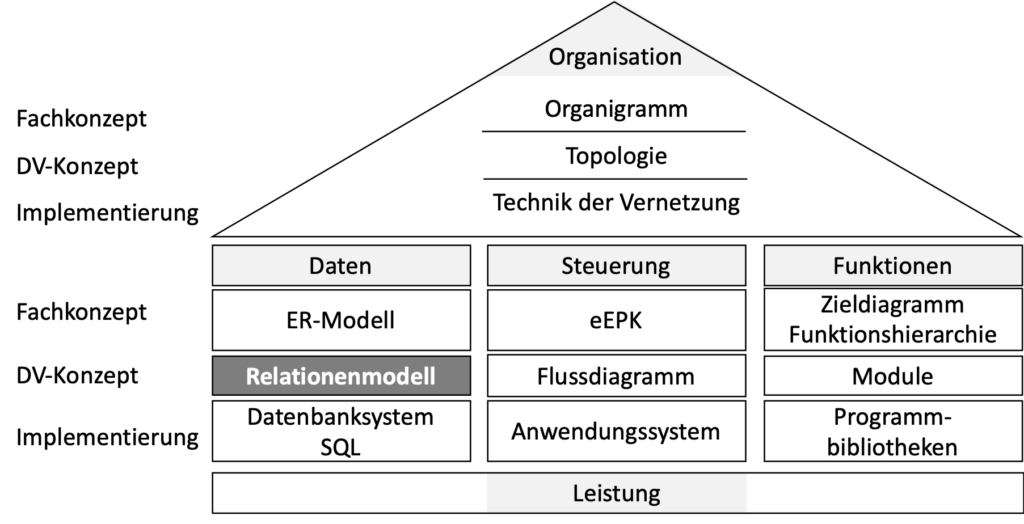
Abb. 1: Einordnung der Datenmodellierung mit Relationen im ARIS-Rahmenkonzept.
Schritt 1: Ausgangspunkt unstrukturierte Daten (Das Problem)
Daten liegen oft in einer Form vor, so dass zwar Menschen mit den Daten arbeiten können, es jedoch schwer bis unmöglich ist, Computerprogramme für die Verarbeitung zu entwickeln.
Als Veranschaulichungs-Beispiel sollen die Dokumentationspflichten eines Hobbyimkers dienen. Ein Hobbyimker soll aufschreiben, was er wann mit seinen Bienen tut. (Das Folgende gilt für alle Wissenssammlungen und Dokumentationen und ist nicht auf das Beispiel des Hobbyimkers beschränkt) Ein solches „Imker-Logbuch“ in einem Notizbuch oder als einfache Textdatei könnte wie folgt aussehen:
Imker-Logbuch 2021 5.5.2021 B1902 Gewicht vor 16,61, nach 14,7 Honigzarge schön ausgebaut noch nicht ganz voll,Neue Honigzarge gegeben Zwei verdeckte Weiselzellen gefunden Ableger aus vier Waben (1 Honig, 1 Pollen 2 alt und verdeckte Brut) -> B2103 Fünf Zargen sind unpraktisch Neuer Ableger B2103 1 Honig, Pollen und 2 alte Brut, 4,8 kg 01.05.2021 Kontrolle Ableger B2101, B2102 Volk B2101 B2102 Kennzeichen blauer Deckel brauner Deckel Sensor grün rot Gewicht 28.04 kg 4,95 4,55 Gewicht 01.05. kg 4,70 4,30 Flug wenig, zielgerichtet wenig, orientierend
Abb. 2: Beispiel unstrukturiertes Imker-Logbuch für die Kontrollen an Bienenstöcken
Schritt 2: Strukturierungsversuch „aufgeräumter aufschreiben“ (Die Verbesserungsidee)
Mit dem unstrukturierten Logbuch ist der wesentliche Schritt getan: Die Daten sind verschriftlicht und damit festgehalten. Allerdings wird der Hobbyimker, wenn er mit vielen Bienenvölkern und über Jahre arbeitet, irgendwann in seinen Aufzeichnungen nichts mehr wiederfinden. Im nächsten Schritt könnte der Hobbyimker seine Notizen etwas aufgeräumter und systematischer anfertigen.
Imker-Logbuch 2021 Datum: 5.5.2021 Aktivität: Kontrolle Volk: B1902 Gewicht vor Bearbeitung: 16,61 Gewicht nach Bearbeitung: 14,7 Honigzarge Ausbau: gut Weiselzellen: 2 Änderung: „neue Honigzarge“ Änderung: „Ableger neu B2103“ Anmerkung: „Fünf Zargen sind unpraktisch“ Datum: 01.05.2021 Aktivität: „Kontrolle“ Volk: „B2101“ Gewicht vor Bearbeitung: 4,95 Flugaktivität: wenig Flugbild: zielgerichtet Volk: „B2102 Gewicht vor Bearbeitung: 4,55 Flugaktivität: wenig Flugbild: zielgerichtet ….
Abb. 3: Beispiel „aufgeräumtes“ Logbuch.
In dem aufgeräumten Logbuch finden sich Menschen bereits gut zurecht, für Computerprogramme sollte es formal noch strukturierter sein.
Schritt 3: Umsetzung in ein einfaches Relationenmodell (Die Lösung)
Zunächst sollte der Hobbyimker analysieren, welche Daten er denn häufig erfassen möchte. Das aufgeräumte Logbuch gibt dazu Hinweise:
1. Datum der Kontrolle 2. Bezeichnung des Volkes als Zeichenkette/Text, z.B. „B2102“ 3. Gewicht des Volkes in kg als Fließkommazahl, z.B. 4,55 4. Bewertung der Flugaktivität. Hier entscheidet sich der Imker, Zahlen wie für Schulnoten zu vergeben, z.B. 1 für hohe Aktivität und 5 für gar keine Aktivität. 5. Bewertung des Flugbildes als Zeichenkette/Text, z. B. „zielgerichtet“ oder „suchend“ 6. Änderungen sieht der Imker als Zeichenkette vor. Mehr als zwei Änderungen führt er normalerweise nicht durch. 7. Als Anmerkung möchte der Imker noch Bemerkungen in Textform festhalten. 8. Eine laufende Nummer macht es einfacher, eine bestimmte Kontrolle später wiederzufinden.
Abb. 4: Beispiel Analyse der Daten für das Imker-Logbuch
Wir nutzen nun sogleich die von Codd vorgeschlagene Schreibweise für eine Relation. Eine vertiefte Beschreibung, was es mit der Relation auf sich hat, finden Sie in den folgenden Abschnitten.
Aus der Analyse ergibt sich die Relation.
logeintrag ( lfd_nr, datum, volk, gewicht, flugaktiv, flugbild, aenderung1, aenderung2, anmerkung )
Abb. 5 : Beispiel für die Einträge im Imker-Logbuch. Das Relationenschema für das Imker-Logbuch besteht nur aus dieser einen Relation.
Den Kontrollen werden dann konkrete Tupel (= Datensätze) zugeordnet. Es fällt auf, dass es am 01.05. offensichtlich keine Gründe gab, Änderungen oder Anmerkungen festzuhalten.
logeintrag ( 35, 01.05.2021, B2101, 4,95, 4, „zielgerichtet“, , , ) logeintrag ( 36, 01.05.2021, B2102, 4,55, 4, „zielgerichtet“, , , )
Abb. 6: Beispiel zwei Datensätze einer Kontrolle als Relationen formuliert
Es gibt mehrere Möglichkeiten, die Relation praktisch zu implementieren – von einer einfachen handschriftlichen Tabelle auf Papier bis hin zu einer Smartphone-App mit einem relationalen Datenbankmanagementsystem. In den Folgebeispielen sehen Sie, wie man ein Relationenmodell zur Konzeption entwickelt.
Relationen sind fast wie Tabellen
Eine Relation ist die Basis der von Edgar F. Codd (1970) entwickelten relationalen Algebra. Mathematisch ist das anspruchsvoll, für den praktischen Nutzen können wir die Ideen allerdings stark vereinfachen. Wenn immer möglich, werden Sie über Begrifflichkeiten von Tabellenkalkulationsprogrammen wie Microsoft Excel an die relationale Sichtweise herangeführt. Statt Excel wären auch Numbers (Apple) oder das freie System Open Office Calc oder Gnumeric (Linux) als Beispiele geeignet. Eine Relation besteht aus einer Bezeichnung (vgl. Arbeitsblatt-Name in Excel), aus Attributen (vgl. Spaltenüberschriften in Excel-Tabellen) und Tupeln (vgl. Zeilen in einer Excel-Tabelle). Ein Attribut beschreibt den Typ eines möglichen Attributwertes und bezeichnet ihn mit einem Attributnamen. Ein Tupel stellt eine konkrete Kombination von Attributwerten dar (einen Datensatz). Das Relationenmodell beschreibt Daten also in einer Form, die sich gut in Tabellen übersetzen lässt. Stellen Sie sich ein Schraubenlager vor, in dem Sie über Ihre Schrauben Buch führen wollen. Eine Schraube hat dann die Eigenschaften „Typ“ (z.B. „Rundkopf“), einen Durchmesser in mm, eine Länge in mm und eine Materialsorte (z.B. „Messing“). Mit Blick auf die spätere Umsetzung verzichten manche auf Groß-Kleinschreibung und auf Umlaute.
schraube (id, typ, durchmesser, laenge, material)
Abb. 7: Beispiel für ein Relationsschema mit einer Relation für Schrauben in der Schreibweise von Codd
In der Übersicht in Tab.1 sind die Begriffe der Relationentheorie lebensweltlichen Begriffen gegenübergestellt:
| RELATIONENTHEORIE | KANN VERDEUTLICHTE WERDEN DURCH |
| Relation | Tabelle |
| Tupel | Menge der Zellen in einer Zeile, Datensatz |
| Attribut | Spaltenüberschrift |
Tab. 1: Begriffe aus der Relationentheorie im Vergleich zu Tabellen
Die schon verwendeten Begriffe „Schema“ und „Tupel“ sollen nun noch einmal präziser gefasst werden.
Ein Schema, Datenschema oder Relationsschema ist eine formale Beschreibung der Struktur von Daten.
Abb. 8: Begriffsdefinition „Schema“
Ein Tupel ist eine geordnete Wertesammlungen und wird – in der Relationentheorie – als Synonym für einen Datensatz verwendet. Die Werte eines Tupels sind die Attribute (Synonym für Attribut ist ein Datenfeld). Ein „n-Tupel“ oder verkürzt „Tupel“ bezeichnet somit eine Sammlung mit einer beliebigen Anzahl n von Attributen.
Abb. 9: Begriffsdefinition „Tupel“
Was ist eine Relation?
Mathematik: In der Mathematik ist eine Relation die Beziehung zwischen Dingen. Eine Relation R ist eine Menge von Tupeln. Dinge, die zueinander in der Relation R stehen, bilden ein Tupel, das Element von R ist. So gesehen ist eine Relation die Menge aller Kombinationen der möglichen Attributwerte. In der Mathematik sind meist zweiwertige Relationen von Interesse (z.B. mit den Attributen „person“ und „telefonnr“), in der Informatik finden oft mehrwertige Relationen (z.B. die Schrauben mit fünf Attributen). Haben Sie z. B. drei Personen und vier Telefonnummern, so besteht die zweiwertige Relation theoretisch aus maximal person X telefonnr Elementen, also 3*4=12 Tupeln. Praktisch werden Sie aber nur eine Teilmenge davon haben, z.B. 3 Tupel, wenn jede der drei Personen nur eine Telefonnummer hat. Eine Relation ist daher, mathematisch gesprochen, eine Teilmenge des karthesischen Produktes der Attribute. Das kartesische Produkt M×N zweier Mengen M und N ist die Menge aller geordneten Paare mit erster Komponente aus M und zweiter Komponente aus N. Ein geordnetes Paar (x, y) besteht aus zwei Werten x und y, wobei x die erste und y die zweite Komponente ist.
Praktisch: In der Informatik ist eine Relation eine Sammlung von Datensätzen (=Tupeln), die alle jeweils gleich aufgebaut sein müssen: Ein Datensatz besteht aus einer Reihe von 1 bis n Datenfeldern (=Attributen). Die Reihenfolge bzw. Anordnung der Datenfelder ist wesentlich. Die einzelnen Datenfelder haben eine Bezeichnung (Attributnamen). Wenn Sie vorhaben, Ihre Daten technisch in einem relationalen Datenbankmanagementsystem zu organisieren, können Sie eine Relationen durch eine Tabelle beschreiben. Dann sind die Tupel die Zeilen mit den konkreten Datensätzen, die Attributnamen sind die Spaltenbezeichnungen. Die Reihenfolge der Spalten ist wesentlich. Die Reihenfolge der Zeilen ist allerdings beliebig.
Dem Begriff „Relation“ können Sie sich also über die Eigenschaften einer Relation nähern:
1. Es gibt keine zwei völlig identischen Tupel. Das heißt: Zwei Tupel (Zeilen in einer Tabelle, Datensätze) unterscheiden sich in mindestens einem Attribut (Wert). 2. Die Reihenfolge der Tupel ist unwichtig, sie sind nicht geordnet. (Es ändert erst einmal nichts, wenn die Reifenfolge der Zeilen geändert wird.) 3. Die Reihenfolge der Attribute ist wichtig, sie sind geordnet. (Diese Eigenschaft ist in der Historie und der Ableitung von den mathematischen Relationen geschuldet. Praktisch hat es bei klug gewählten Spaltenüberschriften keine Relevanz.) 4. Alle Attribute sind atomar (In jeder Tabellenzelle darf nur ein Eintrag einer Sorte stehen. In ein Tabellenfeld gehört nur ein Wert.). Wenn alle Werte atomar sind, befindet sich das Relationenmodell in der ersten Normalform. Das is mit die wichtigste Eigenschaft.
Abb. 10: Beispiel für die Implementierung einer einfache Relation in eineTabelle am Beispiel Schrauben.
Aus dem vorgenannten lässt sich der Begriff Relation schärfer fassen.
Eine Relation ist eine Menge von Tupeln bzw. Datensätzen. Die Tupel bestehen alle aus der gleichen Anzahl von Datenfeldern oder Attributen. Die Datenfelder oder Attribute sind immer in der gleichen Reihenfolge angeordnet. In jedem Datenfeld steht immer nur ein Wert. In jedem Datenfeld in einer bestimmten Position steht immer die gleiche Art von Wert.
Abb. 11: Begriffsdefinition „Relation“
Implementierung von Relationen
Implementierung von Relationen als Tabellen
In den meisten Fällen werden Ihnen Relationen als Tabellen z.B. in relationalen Datenbankmanagementsystemen oder in Excel oder als CSV-Dateien begegnen. Die Umsetzung des Relationenschemas für die Schrauben (Abb. xx) als Tabelle sähe dann wie in Abb. xx aus:
schraube (id, typ, durchmesser, laenge, material)
Abb. 12: Relationenschema mit einer Relation „schraube“
id typ laenge durchmesser material ================================================== 1 Rundkopf 50 4 Messing 2 Rundkopf 30 4 Messing 3 Senkkopf 50 5 vernickelt 4 Senkkopf 30 5 vernickelt .....
Abb. 13: Umsetzung der Relation „schraube“ in eine Tabelle
Eine CSV-Datei (nach RFC 4180) bildet Tabellen in einem einfachen Textformat nach. In einer CSV-Datei werden die Zeilen durch einen Zeilenumbruch mit Wagenrücklauf getrennt (in Programiersprachen mit „\r\n“ bezeichnet) die einzelnen Datenfelder werden normalerweise mit einem Komma getrennt, in Deutschland mit einem Semikolon, da das Komma der Dezimaltrenner ist. Die erste Zeile enthält die Attributnamen.
id;typ;durchmesser;laenge;material\r\n 1;Rundkopf;4;50;Messing\r\n 2;Rundkopf;4;30;Messing\r\n 3;Senkkopf;5;50;vernickelt\r\n 4;Senkkopf;5;30;vernickelt\r\n .....
Abb. 14
Implementierung von Relationen als Schlüssel-Wert-Paare
Ein Relationenschema kann, muss aber nicht als Sammlung von Tabellen implementiert werden. Eine andere Möglichkeit ist die technische Speicherung als Schüssel-Wert-Paare in einer einfachen Textdatei. So wird beispielsweise bei JSON-formatierten Daten (nach RFC 8259) verfahren. Für das Beispiel der Schrauben hieße das:
{
id:1
typ:Rundkopf
durchmesser:4
laenge:50
material:Messing
}
{
id:2
typ:Rundkopf
durchmesser:4
laenge:30
material:Messing
}
....
Abb. 15: Implementierung der Relation „schraube“ als Schlüssel-Wert-Paare.
Implementierung von Relationen in XML
Ein Relationenschema kann auch XML-formatiert (standardisiert vom W3C) implementiert werden. Für das Beispiel der Schrauben sähe eine XML-Darstellung wie in Abb. xx aus.
<schraube> <id>1</id> <typ>Rundkopf</typ> <durchmesser>4</durchmesser> <laenge>50</laenge> <material>Messing</material> </schraube> <schraube> <id>2</id> <typ>Rundkopf</typ> <durchmesser>4</durchmesser> <laenge>30</laenge> <material>Messing</material> </schraube> ....
Abb. 16: Implementierung der Relation „schraube“ als XML-formatierte Textdatei.
Umgang mit komplexeren Beziehungen zwischen Relationen
Allgemeiner Fall, komplexe Struktur am Beispiel einer Telefonliste
Das relationale Modell spielt seine Stärken dann aus, wenn Daten eine komplexere Struktur haben. So kann es im Imker-Logbuch-Beispiel vorkommen, dass es vielleicht mehr als zwei Änderungen bei einem Logbucheintrag gibt. Oder aber Personen haben mehrere Telefonnummern und teilen sich vielleicht in Bürogemeinschaft eine Nummer. Das Telefonnummernbeispiel soll nun dazu dienen, die Beziehung zwischen mehreren Relationen zu erläutern.
Das Problem: Würden Sie den Fall, dass Personen mehrere Telefone haben und sich vielleicht mehrere Personen ein Telefon teilen, durch eine Relation darstellen wollen, müssten Sie für eine Vielzahl von Telefonen, z.B. drei, jeweils Attributnamen vorsehen. In der Implementierung als Tabelle wird das zu einer „löchrigen“ Tabelle mit vielen ungefüllten Feldern führen. Wenn dann die erste Person mit vier Telefonen auftaucht, müssten Sie das Relationenschema ändern und auch die Struktur der gesamten Datenbank.
telefon_von (id, name, telnr1, telnr2, telnr3)
Abb. 17: Beispiel für ein Relationsschema für die Telefonliste in der Schreibweise von Codd
id name tel1 tel2 tel3 ===================================================== 1 Schmidt 0186-233 -3351 0172 1234567 2 Müller -3351 0177 1234567 3 Mayer 0184-223
Abb. 18: Umsetzung der Relation für eine Telefonliste als Tabelle
Die Lösung der o.a. Probleme (löchrige Tabelle oder ggf. nicht genug Felder in einem Tupel) ist, mit mehreren Relationen zu arbeiten und eine Beziehung zwischen den Relationen über gleiche Attributnamen herzustellen (Abb. xx).
person person_hat_tel telefonnummer p_id name p_id t_id t_id telefon ============= ========== ================== 1 Schmidt 1 1 1 0172 1234567 2 Müller 1 3 2 0177 1234567 3 Mayer 1 3 3 -3351 2 3 4 0186-233 2 2 5 0186-233 3 5
Abb. 19: Beispiel dicht gefüllte Tabellen, die Telefonliste ist auf drei Tabellen aufgeteilt
Mit den drei Tabellen können Sie nun eine Beziehung der möglichen Telefonnummern (Tabelle „telefonnummer“) zu den möglichen Personen (Tabelle „person“) herstellen, in dem Sie zunächst die id der betreffenden Person heraussuchen, dann die Telefon-Ids (t_id) suchen, die in der Tabelle person_hat_tel der jeweiligen Personen-Id (p_id) zugeordnet sind und dann alle Telefonnummern herausschreiben, die Sie mit den Telefon-Ids in der Tabelle „telefonnummer“ finden. Dieser Finde-Algorithmus lässt sich im Übrigen leicht programmieren, so dass sich diese Art der Datenorganisation in relationalen Systemen durchgesetzt hat.
Das Relationenschema zu den drei Tabellen aus Abb. xx besteht aus drei Relationen wie in Abb. xx
person (p_id, name) telefonnummer (t_id, telefon) person_hat_tel (p_id, t_id)
Abb. 20: Relationenschema mit drei Relationen für komplexere Datenbeziehungen m-zu-n
Im in Abb. 20 dargestellten Fall handelt es sich im übrigen um eine sogenannte m-zu-n Beziehung, da grundsätzlich jeder Person beliebig viele (n) Telefonnummern zugeordnet werden können, andererseits aber eine Telefonnummer theiretisch auch von beliebig vielen (m) Personen genutzt werden kann.
Die Ids p_id und t_id in den Relationen person und telefonnummer sind Primärschlüssel, Die gleichnamigen Ids in der Relation „person_hat_tel“ sind Fremdschlüssel.
Mit der Aufteilung der Telefonliste auf drei Relationen befindet sich das Relationenschema in der zweiten Normalform, da jedes Attribut in jeder Relation vom Primärschlüssel abhängig ist.
Primärschlüssel und Fremdschlüssel
Der Primärschlüssel wird zur eindeutigen Identifizierung eines Tupels (=Datensatzes) verwendet.
Der Wert eines Primärschlüssels muss einmalig sein, da er jeden Datensatz eindeutig kennzeichnet. Beispiele wären für Menschen die Personalausweis-ID, bei Studentinnen die Matrikel-Nummer oder im Sportverein die Mitgliedsnummer. Der Primärschlüssel einer Relation kann drei Ausprägungen haben und ein eindeutiger, ein zusammengesetzter oder ein künstlicher Primärschlüssel sein. Die hier verwendeten zusätzlichen Ids sind künstliche Primärschlüssel.
Auf künstliche Primärschlüssel kann verzichtet werden, wenn es einen eindeutigen Primärschlüssel oder einen zusammengesetzten Primärschlüssel gibt.
Bei einem eindeutigen Primärschlüssel handelt es sich um ein Attribut, das einen Datensatz eindeutig kennzeichnet. Das liegt nicht immer vor: Der Nachname beispielsweise ist ungeeignet, da es oft mehrere Menschen mit Nachnamen „Schmidt“ gibt.
Ein zusammengesetzter Primärschlüssel besteht aus mehreren Attributen, die zusammen ein Tupel eindeutig kennzeichnen.
Es hat sich in der Praxis bewährt, spätestens bei der Implementierung in ein RDBMS künstliche Primärschlüssel für jede Tabelle zu verwenden.
Ein Fremdschlüssel ist ein Attribut, das auf einen Primärschlüssel in einer anderen Relation verweist und damit die Beziehung zwischen Relationen herstellt.
Sonderfall „ein bisschen komplexe Datenbeziehungen“
Für den etwas einfacheren Fall, dass eine Person zwar mehrere Telefone haben kann, aber es nie vorkommt, dass ein Telefon mehreren Personen zugeordnet ist, vereinfacht sich das relationale Modell auf zwei Relationen. Die notwendige Beziehung zwischen Personen und den Telefonen wird dadurch hergestellt, dass jedem Telefon eine Personen-Id zugeordnet wird. Die Relation „telefon“ erhält dazu ein weiteres Attribut p_id. Das Attribut p_id in der Relation „telefon“ ist ein Fremdschlüssel, in der Relation „person“ ist p_id ein Primärschlüssel und kennzeichnet ein Tupel (einen Datensatz) eindeutig.
person (p_id, name) telefonnummer (t_id, telefon, p_id)
Abb. 21: Relationenschema für eine weniger komplexe Datenbeziehungen 1-zu-n
Eine solche Form der Beziehung zwischen Relationen heißt 1-zu-n Beziehung.
Sonderfall „ganz einfache Datenbeziehung“
Der ganz einfache Fall, dass zu jeder Person genau eine Telefonnummer gibt, eine sogenannte 1-zu-1 Beziehung, können Sie durch eine einzelne Relation darstellen. Das heißt, Sie fassen die realweltlichen Objekte Person und Telefon zu einer Relation zusammen und haben keine direkte Zuordnung mehr zwischen den Objekten in der Realität und der modellhaften Vorstellung in Form von Relationen.
person (id, name, telefon)
Abb. 22: Relationenschema für ganz einfache Datenbeziehungen 1-zu-1
Anwendung der Datenmodellierung mit Relationen auf die Fallstudie der Kaffeemanufaktur
Die Fallstudie für die Kaffeemanufaktur führt zur Datenhaltung aus:
Kaffeemanufaktur „Kleiner Schwarzer“ goes cloud computing – Datenhaltung und User Interface Daten in Excel Das Excel-Arbeitsblatt verkauf.xlsx hat sich Frau Malzkanne selber gebaut. Es besteht aus acht Spalten mit Nummern „laufende Nummer“, „Datum“, „Kundenname“, Anzahl Brasil Santos“, „Anzahl Espresso“, „Anzahl Omas Bester“, „Betrag netto“, „Betrag brutto“. Martin Malzkanne soll als Ersatz für das Excel-Arbeitsblatt verkauf.xlsx in eine Internet-Anwendung programmieren, in die Frau Malzkanne dann zukünftig die Verkäufe eintragen kann. Martin Malzkanne zeichnet dazu ein Use-Case-Diagramm, um mit Melitta Malzkanne zu diskutieren, was sie mit der Internet-Anwendung tun können sollte. Ebenso soll Frau Malzkanne das Datenmodell (Relationenmodell oder ERM) für diese Daten zeichnen, damit Martin Malzkanne die Datenbank anlegen kann.
Abb. 23: Auszug aus der Fallstudie
Das Relationenschema, das Frau Malzkanne erstellen soll, ist eines für eine „einfache Datenstruktur“ und besteht aus nur einer Relation. Die Id ist in diesem Fall die laufende Nummer.
verkauf (lfd_nr, datum, kd_name, anz_brasil_santos, anz_espresso, anz_oma_best, netto, brutto)
Abb. 24: Relationenmodell für den Verkaufsprozess in der Fallstudie
Damit ist die Aufgabenstellung zunächst erledigt. Wenn Sie weiter denken, ziehen Sie vielleicht ein Wachstum des Unternehmens in Betracht, und es werden Kaffeesorten hinzukommen. Sie werden dann mit mehreren Relationen arbeiten, in diesem Fall wird das Datenmodell ungleich komplizierter. Für den Start genügt das einfache Modell.
Quellen
Codd, E. (1970): A Relational Model of Data for Large Shared Data Banks” Communications of the ACM, San Jose, CA, USA, 1970. ACM, New York, USA, 1970; S. 377-387. IBM Research Laboratory, San Jose, California. Online Ressource: https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf